Nguồn: Công nghệ Tencent
Kể từ Tết Nguyên đán, mức độ phổ biến của DeepSeek vẫn tiếp tục tăng, cùng với nhiều hiểu lầm và tranh cãi. Một số người nói rằng đó là "niềm tự hào của các sản phẩm trong nước đánh bại OpenAI", trong khi những người khác nói rằng đó "chỉ là một cách thông minh để sao chép các bài tập mô hình lớn của nước ngoài".
Những hiểu lầm và tranh cãi này chủ yếu tập trung ở năm khía cạnh:
1. Huyền thoại quá mức và sự hạ thấp vô nghĩa, DeepSeek có thực sự là một sáng kiến cấp thấp không? Có cơ sở nào cho cái gọi là ChatGPT chưng cất không?
2. Chi phí của DeepSeek thực sự chỉ là 5,5 triệu đô la Mỹ?
3. Nếu DeepSeek thực sự hiệu quả như vậy, thì liệu khoản đầu tư khổng lồ vào AI của các tập đoàn toàn cầu lớn có bị lãng phí không?
4. DeepSeek có sử dụng lập trình PTX không? Nó có thực sự có thể bỏ qua sự phụ thuộc vào Nvidia CUDA không?
5. DeepSeek rất phổ biến trên toàn thế giới, nhưng liệu nó có bị cấm ở các quốc gia khác do vấn đề tuân thủ, địa chính trị và các vấn đề khác không?
1. Huyền thoại quá mức và sự hạ thấp vô nghĩa DeepSeek có thực sự là một sáng kiến cấp cơ sở không?
Caoz, một chuyên gia Internet, tin rằng giá trị của nó trong việc thúc đẩy sự phát triển của ngành công nghiệp này đáng được ghi nhận, nhưng vẫn còn quá sớm để nói về sự lật đổ. Theo một số đánh giá chuyên môn, nó không vượt trội hơn ChatGPT trong việc giải quyết một số vấn đề chính.
Ví dụ, một người nào đó đã thử nghiệm mã để mô phỏng sự nảy của một quả bóng thông thường trong không gian kín. Hiệu suất của chương trình do DeepSeek viết vẫn khác so với ChatGPT o3-mini về mặt tuân thủ vật lý.
Đừng thần thoại hóa nó quá mức, nhưng cũng đừng vô tình hạ thấp nó.
Hiện tại có hai quan điểm cực đoan về những thành tựu công nghệ của DeepSeek: một quan điểm gọi bước đột phá về công nghệ của công ty là "cuộc cách mạng mang tính đột phá"; quan điểm còn lại cho rằng đây chỉ là bản sao chép các mô hình nước ngoài, thậm chí còn có suy đoán rằng công ty đã đạt được tiến bộ bằng cách sao chép mô hình OpenAI.
Microsoft cho biết DeepSeek đã trích xuất kết quả của ChatGPT, vì vậy một số người đã lợi dụng vấn đề này và coi thường DeepSeek là vô giá trị.
Thực ra, cả hai quan điểm đều quá thiên vị.
Nói chính xác hơn, bước đột phá của DeepSeek là nâng cấp mô hình kỹ thuật nhằm giải quyết những điểm khó khăn của ngành, mở ra con đường mới "ít hơn là nhiều hơn" cho lý luận AI.
Nó chủ yếu tạo ra những đổi mới ở ba cấp độ:
Đầu tiên, bằng cách thu gọn kiến trúc đào tạo - ví dụ, thuật toán GRPO đơn giản hóa các thuật toán phức tạp thành các giải pháp kỹ thuật có thể được triển khai bằng cách loại bỏ mô hình Critic (tức là thiết kế "động cơ kép") cần thiết trong học tăng cường truyền thống;
Thứ hai, nó áp dụng các tiêu chuẩn đánh giá đơn giản. Ví dụ, trong các tình huống tạo mã, kết quả biên dịch và tỷ lệ vượt qua bài kiểm tra đơn vị được sử dụng trực tiếp thay vì chấm điểm thủ công. Hệ thống quy tắc xác định này giải quyết hiệu quả vấn đề thiên vị chủ quan trong đào tạo AI;
Cuối cùng, nó tìm thấy sự cân bằng tinh tế trong chiến lược dữ liệu. Bằng cách kết hợp chế độ Zero cho phép tiến hóa tự chủ thuật toán thuần túy với chế độ R1 chỉ yêu cầu hàng nghìn dữ liệu được gắn nhãn thủ công, nó vẫn giữ được khả năng tiến hóa tự chủ của mô hình trong khi vẫn đảm bảo khả năng diễn giải của con người.
Tuy nhiên, những cải tiến này không phá vỡ ranh giới lý thuyết của học sâu, cũng không hoàn toàn lật đổ mô hình kỹ thuật của các mô hình hàng đầu như OpenAI o1/o3. Thay vào đó, chúng giải quyết các điểm khó khăn của ngành thông qua tối ưu hóa cấp hệ thống.
DeepSeek hoàn toàn là mã nguồn mở và ghi lại chi tiết những đổi mới này, cho phép thế giới sử dụng những tiến bộ này để cải thiện quá trình đào tạo mô hình AI của họ. Những đổi mới này có thể được thấy trong các tài liệu nguồn mở.
Tanishq Mathew Abraham, cựu giám đốc nghiên cứu tại Stability AI, cũng đã nêu bật ba cải tiến của DeepSeek trong một bài đăng trên blog gần đây:
1. Cơ chế chú ý đa đầu: Các mô hình ngôn ngữ lớn thường dựa trên kiến trúc Transformer và sử dụng cái gọi là cơ chế chú ý đa đầu (MHA). Nhóm DeepSeek đã phát triển một biến thể của cơ chế MHA có thể sử dụng bộ nhớ hiệu quả hơn và đạt hiệu suất tốt hơn.
2. GRPO với phần thưởng có thể xác minh: DeepSeek chứng minh rằng một quy trình học tăng cường (RL) rất đơn giản thực sự có thể đạt được kết quả giống như GPT-4. Quan trọng hơn, họ đã phát triển một biến thể của thuật toán học tăng cường PPO có tên là GRPO, hiệu quả hơn và hoạt động tốt hơn.
3. DualPipe: Khi đào tạo các mô hình AI trong môi trường nhiều GPU, cần phải xem xét nhiều yếu tố liên quan đến hiệu quả. Nhóm DeepSeek đã đưa ra một phương pháp mới có tên là DualPipe, hiệu quả và nhanh hơn đáng kể.
"Chưng cất" theo nghĩa truyền thống đề cập đến việc đào tạo xác suất mã thông báo (logits), nhưng ChatGPT không mở loại dữ liệu này, vì vậy về cơ bản không thể "chưng cất" ChatGPT.
Do đó, xét về mặt kỹ thuật, không nên nghi ngờ những thành tựu của DeepSeek. Vì quá trình suy luận chuỗi suy nghĩ liên quan đến OpenAI o1 chưa bao giờ được công khai nên rất khó để đạt được kết quả này chỉ bằng cách dựa vào "chưng cất" ChatGPT.
Caoz tin rằng DeepSeek có thể đã sử dụng một phần thông tin ngữ liệu đã được chắt lọc trong quá trình đào tạo hoặc đã thực hiện một chút xác minh chắt lọc, nhưng điều này sẽ không ảnh hưởng nhiều đến chất lượng và giá trị của toàn bộ mô hình.
Ngoài ra, việc tối ưu hóa mô hình của riêng mình dựa trên xác minh chưng cất mô hình hàng đầu là một hoạt động thường xuyên đối với nhiều nhóm mô hình lớn. Tuy nhiên, nó đòi hỏi một API Internet và thông tin có thể thu được rất hạn chế, điều này không có khả năng là yếu tố quyết định. So với lượng thông tin dữ liệu Internet khổng lồ, kho dữ liệu có thể thu được bằng cách gọi mô hình lớn hàng đầu thông qua API chỉ là muối bỏ bể. Có thể đoán hợp lý rằng nó được sử dụng nhiều hơn để xác minh và phân tích các chiến lược hơn là được sử dụng trực tiếp cho đào tạo quy mô lớn.
Tất cả các mô hình lớn đều cần phải lấy dữ liệu huấn luyện từ Internet, và các mô hình lớn hàng đầu cũng liên tục đóng góp dữ liệu cho Internet. Theo quan điểm này, mọi mô hình lớn hàng đầu đều không thể thoát khỏi số phận bị thu thập và chưng cất, nhưng không cần phải coi đây là chìa khóa thành công hay thất bại.
Cuối cùng, mọi người đều là một phần của nhau và chúng ta tiến về phía trước theo từng bước lặp đi lặp lại.
Thứ hai, DeepSeek chỉ tốn 5,5 triệu đô la?
Chi phí là 5,5 triệu đô la. Kết luận này vừa đúng vừa sai vì nó không nêu rõ chi phí là bao nhiêu.
Tanishq Mathew Abraham đã ước tính khách quan chi phí của DeepSeek:
Trước tiên, cần phải hiểu con số này đến từ đâu. Con số này lần đầu tiên xuất hiện trong bài báo DeepSeek-V3, được công bố sớm hơn một tháng so với bài báo DeepSeek-R1;
DeepSeek-V3 là mô hình cơ sở của DeepSeek-R1, điều đó có nghĩa là DeepSeek-R1 thực sự đã thực hiện đào tạo học tăng cường bổ sung trên cơ sở DeepSeek-V3.
Vì vậy, theo một nghĩa nào đó, con số chi phí này tự nó không đủ chính xác vì nó không tính đến chi phí bổ sung cho đào tạo học tăng cường. Tuy nhiên, chi phí bổ sung này có thể chỉ là vài trăm ngàn đô la.

Hình ảnh: Thảo luận về chi phí trong bài báo DeepSeek-V3
Vậy, chi phí 5,5 triệu đô la được nêu trong bài báo DeepSeek-V3 có chính xác không?
Nhiều phân tích dựa trên chi phí GPU, quy mô tập dữ liệu và quy mô mô hình đã đưa ra những ước tính tương tự. Điều đáng chú ý là mặc dù DeepSeek V3/R1 là mô hình có 671 tỷ tham số, nhưng nó sử dụng kiến trúc hỗn hợp chuyên gia, nghĩa là chỉ có khoảng 37 tỷ tham số được sử dụng trong bất kỳ lệnh gọi hàm hoặc truyền tiếp nào, đây là cơ sở để tính toán chi phí đào tạo.
Lưu ý rằng DeepSeek báo cáo chi phí ước tính dựa trên giá thị trường hiện tại. Chúng tôi không biết cụm 2048 GPU H800 (lưu ý: không phải H100, đây là một quan niệm sai lầm phổ biến) của họ thực sự có giá bao nhiêu. Thông thường, mua cụm GPU số lượng lớn sẽ rẻ hơn mua từng phần, do đó chi phí thực tế có thể thấp hơn.
Nhưng điểm quan trọng là đây chỉ là chi phí cho lần chạy thử cuối cùng. Có nhiều thí nghiệm và nghiên cứu cắt bỏ quy mô nhỏ trước khi đạt đến giai đoạn đào tạo cuối cùng, gây tốn kém đáng kể và không được phản ánh trong báo cáo này.
Ngoài ra, còn có nhiều chi phí khác, chẳng hạn như tiền lương của các nhà nghiên cứu. Theo SemiAnalysis, các nhà nghiên cứu của DeepSeek được cho là được trả tới 1 triệu đô la. Mức lương này tương đương với mức lương cao tại các phòng thí nghiệm AGI tiên tiến như OpenAI hoặc Anthropic.
Một số người phủ nhận chi phí thấp và hiệu quả hoạt động của DeepSeek vì sự tồn tại của những chi phí bổ sung này. Tuyên bố này cực kỳ bất công. Bởi vì các công ty AI khác cũng chi rất nhiều tiền cho tiền lương, thường không bao gồm trong chi phí của mô hình. ”
Semianalysis (một công ty nghiên cứu và phân tích độc lập tập trung vào chất bán dẫn và trí tuệ nhân tạo) cũng đã đưa ra phân tích về TCO (tổng chi phí trong lĩnh vực trí tuệ nhân tạo) AI của DeepSeek. Bảng này tóm tắt tổng chi phí của DeepSeek AI khi sử dụng bốn loại GPU khác nhau (A100, H20, H800 và H100), bao gồm chi phí mua thiết bị, xây dựng máy chủ và chi phí vận hành. Dựa trên khoảng thời gian bốn năm, tổng chi phí của 60.000 GPU này là 2,573 tỷ đô la Mỹ, chủ yếu là chi phí mua máy chủ (1,629 tỷ đô la) và chi phí vận hành (944 triệu đô la).
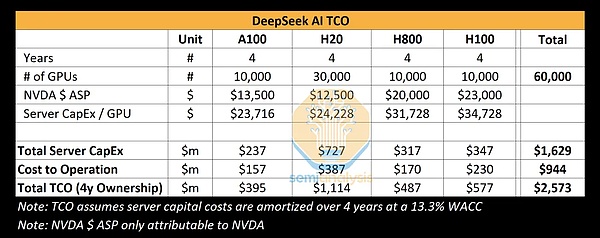
Tất nhiên, không ai bên ngoài biết chính xác DeepSeek có bao nhiêu thẻ và tỷ lệ của từng mô hình là bao nhiêu. Mọi thứ chỉ là ước tính.
Tóm lại, nếu tính toán tất cả các chi phí về thiết bị, máy chủ, hoạt động, v.v., chi phí chắc chắn sẽ cao hơn nhiều so với 5,5 triệu đô la Mỹ. Tuy nhiên, chi phí năng lực tính toán ròng là 5,5 triệu đô la Mỹ đã rất hiệu quả.
Thứ ba, khoản đầu tư chi phí vốn khổng lồ vào năng lực tính toán chỉ là một sự lãng phí lớn?
Đây là quan điểm được lưu hành rộng rãi nhưng khá phiến diện. Thật vậy, DeepSeek đã chứng minh được lợi thế của mình trong hiệu quả đào tạo và cũng chỉ ra rằng một số công ty AI hàng đầu có thể gặp vấn đề về hiệu quả trong việc sử dụng tài nguyên điện toán. Ngay cả sự sụt giảm trong ngắn hạn của Nvidia cũng có thể liên quan đến sự lan truyền rộng rãi của sự hiểu lầm này.
Nhưng điều này không có nghĩa là việc có nhiều tài nguyên điện toán hơn là điều tồi tệ. Từ Scaling Theo quan điểm của Luật khả năng mở rộng, sức mạnh tính toán lớn hơn luôn có nghĩa là hiệu suất tốt hơn. Xu hướng này vẫn tiếp tục kể từ khi kiến trúc Transformer ra đời vào năm 2017 và mô hình của DeepSeek cũng dựa trên kiến trúc Transformer.
Mặc dù trọng tâm của quá trình phát triển AI liên tục thay đổi - từ quy mô mô hình ban đầu, đến quy mô của tập dữ liệu, đến các phép tính suy luận và dữ liệu tổng hợp hiện tại, nhưng quy luật cốt lõi "tính toán nhiều hơn đồng nghĩa với hiệu suất tốt hơn" vẫn không thay đổi.
Mặc dù Deep Seek đã tìm ra một con đường hiệu quả hơn, quy luật quy mô vẫn có giá trị, nhưng nhiều tài nguyên tính toán hơn vẫn có thể đạt được kết quả tốt hơn.
Thứ tư, DeepSeek có sử dụng PTX để bỏ qua sự phụ thuộc vào NVIDIA CUDA không?
Bài báo của DeepSeek có đề cập rằng DeepSeek sử dụng lập trình PTX (Thực thi luồng song song). Thông qua quá trình tối ưu hóa PTX tùy chỉnh như vậy, hệ thống và mô hình của DeepSeek có thể giải phóng hiệu suất của phần cứng cơ bản tốt hơn.
Văn bản gốc của bài báo như sau:
"chúng tôi sử dụng các lệnh PTX (Thực thi luồng song song) tùy chỉnh và tự động điều chỉnh kích thước khối giao tiếp, giúp giảm đáng kể việc sử dụng bộ đệm L2 và sự can thiệp vào các SM khác." "Chúng tôi sử dụng các lệnh PTX (Thực thi luồng song song) tùy chỉnh và tự động điều chỉnh kích thước khối giao tiếp, giúp giảm đáng kể việc sử dụng bộ đệm L2 và sự can thiệp vào các SM khác."
Có hai cách giải thích về nội dung này đang lưu hành trên Internet. Một ý kiến cho rằng đây là để "bỏ qua sự độc quyền của CUDA"; ý kiến khác cho rằng vì DeepSeek không thể có được các chip cao cấp nhất nên để giải quyết vấn đề băng thông kết nối hạn chế của GPU H800, nó phải hạ xuống mức thấp hơn để cải thiện khả năng giao tiếp giữa các chip.
Dai Guohao, phó giáo sư tại Đại học Giao thông Thượng Hải, tin rằng cả hai tuyên bố đều không chính xác. Trước hết, lệnh PTX (thực thi luồng song song) thực chất là một thành phần nằm bên trong lớp trình điều khiển CUDA và nó vẫn phụ thuộc vào hệ sinh thái CUDA. Do đó, sẽ là sai lầm khi nói rằng PTX có thể vượt qua được thế độc quyền của CUDA.
Giáo sư Dai Guohao đã sử dụng PPT để giải thích rõ ràng mối quan hệ giữa PTX và CUDA:
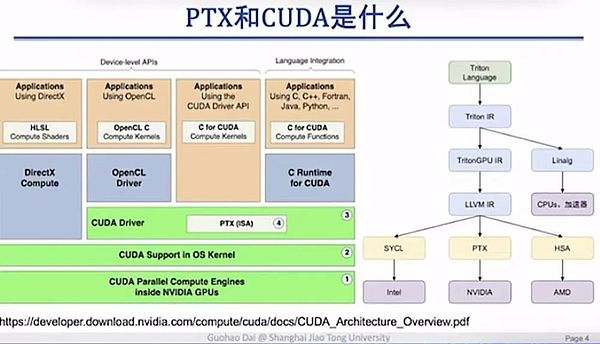
PPT này được thực hiện bởi Dai Guohao, Phó Giáo sư của Đại học Giao thông Thượng Hải
CUDA là một giao diện cấp cao hơn cung cấp một loạt các giao diện lập trình hướng đến người dùng. PTX thường được ẩn trong trình điều khiển CUDA, do đó hầu hết các kỹ sư thuật toán học sâu hoặc mô hình lớn sẽ không được tiếp xúc với lớp này.
Vậy tại sao lớp này lại quan trọng đến vậy? Lý do là chúng ta có thể thấy từ góc nhìn này rằng PTX tương tác trực tiếp với phần cứng cơ bản, cho phép lập trình và gọi phần cứng cơ bản tốt hơn.
Nói một cách đơn giản, giải pháp tối ưu hóa DeepSeek không phải là giải pháp cuối cùng trong điều kiện thực tế của những hạn chế về chip, mà là giải pháp tối ưu hóa chủ động. Bất kể chip được sử dụng là H800 hay H100, phương pháp này đều có thể cải thiện hiệu quả giao tiếp và kết nối.
5. DeepSeek có bị cấm ở nước ngoài không?
Sau khi DeepSeek trở nên phổ biến, năm gã khổng lồ điện toán đám mây NVIDIA, Microsoft, Intel, AMD và AWS đều đã ra mắt hoặc tích hợp DeepSeek. Trong nước, Huawei, Tencent, Baidu, Alibaba và Volcano Engine cũng hỗ trợ triển khai DeepSeek.
Tuy nhiên, có một số nhận xét quá cảm xúc trên Internet. Một mặt, các gã khổng lồ đám mây nước ngoài đã ra mắt DeepSeek và "người nước ngoài đã bị thuyết phục".
Trên thực tế, việc các công ty này triển khai DeepSeek chủ yếu xuất phát từ những cân nhắc về mặt thương mại. Là một nhà cung cấp đám mây, việc hỗ trợ triển khai càng nhiều mô hình phổ biến và có khả năng nhất càng tốt có thể cung cấp dịch vụ tốt hơn cho khách hàng. Đồng thời, họ cũng có thể tận dụng lưu lượng truy cập liên quan đến DeepSeek và có thể mang lại một số chuyển đổi người dùng mới.
Đúng là việc triển khai được tập trung khi DeepSeek rất phổ biến, nhưng những tuyên bố rằng DeepSeek đặc biệt thích nó hoặc rằng công ty đã "choáng ngợp" đều là phóng đại.
Tệ hơn nữa, một số người còn bịa đặt câu chuyện rằng sau khi DeepSeek bị tấn công, giới công nghệ Trung Quốc đã thành lập Liên minh Avengers để cùng nhau hỗ trợ DeepSeek.
Mặt khác, cũng có ý kiến cho rằng vì lý do địa chính trị và các lý do thực tế khác, việc sử dụng DeepSeek sẽ sớm bị cấm ở nước ngoài.
Về vấn đề này, Caoz đã đưa ra một lời giải thích tương đối rõ ràng: Trên thực tế, cái mà chúng tôi gọi là DeepSeek thực chất bao gồm hai sản phẩm, một là DeepSeek, một ứng dụng nổi tiếng thế giới và sản phẩm còn lại là thư viện mã nguồn mở trên GitHub. Cái trước có thể được coi là bản demo của cái sau, một minh chứng đầy đủ về khả năng. Hệ sinh thái nguồn mở sau này có thể phát triển mạnh mẽ.
Ứng dụng DeepSeek bị hạn chế sử dụng, trong khi những gã khổng lồ này có thể truy cập và cung cấp phần mềm nguồn mở DeepSeek. Đây là hai điều hoàn toàn khác nhau.
DeepSeek đã bước vào đấu trường AI toàn cầu với tư cách là "mô hình lớn của Trung Quốc" và áp dụng giao thức nguồn mở hào phóng nhất - Giấy phép MIT, thậm chí còn cho phép sử dụng thương mại. Các cuộc thảo luận hiện tại về vấn đề này đã vượt xa phạm vi đổi mới công nghệ, nhưng tiến bộ công nghệ chưa bao giờ là cuộc tranh cãi trắng đen về đúng sai. Thay vì quá cường điệu hoặc phủ nhận hoàn toàn, tốt hơn là hãy để thời gian và thị trường kiểm chứng giá trị thực sự của nó. Rốt cuộc, trong cuộc đua AI, cuộc cạnh tranh thực sự mới chỉ bắt đầu.
Tài liệu tham khảo:
"Một số hiểu lầm phổ biến về DeepSeek" Tác giả: caoz
https://mp.weixin.qq.com/s/Uc4mo5U9CxVuZ0AaaNNi5g
"Giải mã chuyên nghiệp mạnh mẽ nhất về DeepSeek đã có ở đây, Diễn giải siêu cứng rắn của Giáo sư Qingjiaofu" Tác giả: ZeR0
https://mp.weixin.qq.com/s/LsMOIgQinPZBnsga0imcvA
Phá vỡ ảo tưởng DeepSeek Tác giả: Tanishq Mathew Abraham, cựu giám đốc nghiên cứu tại Stability AI
https://www.tanishq.ai/blog/posts/deepseek-delusions.html


 Weatherly
Weatherly