Source: Tencent Technology
Since the Spring Festival, DeepSeek's popularity has continued to rise, accompanied by many misunderstandings and controversies. Some people say it is "the light of domestic products that beat OpenAI", while others say it is "just a clever way of copying foreign large-scale model homework".
These misunderstandings and controversies are mainly concentrated in five aspects:
1. Excessive myth and mindless devaluation, is DeepSeek really an underlying innovation? Is there any basis for the so-called distillation ChatGPT?
2. Is the cost of DeepSeek really only 5.5 million US dollars?
3. If DeepSeek can really be so efficient, then are the huge AI capital expenditures of major global giants all in vain?
4. Does DeepSeek use PTX programming? Can it really bypass the dependence on Nvidia CUDA?
5. DeepSeek is popular all over the world, but will it be banned abroad one after another due to compliance, geopolitical and other issues?
1. Excessive myth and mindless denigration Is DeepSeek really an underlying innovation?
Internet practitioner Caoz believes that its value in promoting the development of the industry is worthy of recognition, but it is too early to talk about subversion. According to some professional evaluations, it has not surpassed ChatGPT in solving some key problems.
For example, someone tested the code that simulates the bouncing of a typical ball in a closed space. Compared with ChatGPT o3-mini, the performance of the program written by DeepSeek is still different from that of ChatGPT o3-mini in terms of compliance with physics.
Don't over-mythologize it, but don't mindlessly denigrate it.
There are currently two extreme views on DeepSeek's technical achievements: one calls its technological breakthrough a "disruptive revolution"; the other believes that it is just an imitation of foreign models, and there is even speculation that it has made progress by distilling the OpenAI model.
Microsoft said that DeepSeek distilled the results of ChatGPT, so some people took advantage of the issue to belittle DeepSeek.
In fact, both views are too one-sided.
To be more precise, DeepSeek's breakthrough is an engineering paradigm upgrade aimed at industry pain points, opening up a new path of "less is more" for AI reasoning.
It has made innovations on three levels:
First, it slims down the training architecture - for example, the GRPO algorithm simplifies complex algorithms into engineering solutions that can be implemented by eliminating the Critic model (i.e., the "dual engine" design) that is required in traditional reinforcement learning;
Second, it adopts simple evaluation standards, such as directly replacing manual scoring with compilation results and unit test pass rates in code generation scenarios. This deterministic rule system effectively solves the problem of subjective bias in AI training;
Finally, it finds a subtle balance in data strategy, combining the Zero mode of pure algorithm autonomous evolution with the R1 mode that only requires thousands of manually labeled data, which not only retains the model's autonomous evolution capability but also ensures human interpretability.
However, these improvements have not broken through the theoretical boundaries of deep learning, nor have they completely overturned the technical paradigms of head models such as OpenAI o1/o3, but have solved the industry's pain points through system-level optimization.
DeepSeek is completely open source and records these innovations in detail, and the world can use these advances to improve their own AI model training. These innovations can be seen from the open source files. Tanishq Mathew Abraham, former research director of Stability AI, also highlighted three innovations of DeepSeek in a recent blog post: 1. Multi-head attention mechanism: Large language models are usually based on the Transformer architecture, using the so-called multi-head attention (MHA) mechanism. The DeepSeek team has developed a variant of the MHA mechanism that can both use memory more efficiently and achieve better performance. 2. GRPO with verifiable rewards: DeepSeek proves that a very simple reinforcement learning (RL) process can actually achieve similar results to GPT-4. More importantly, they developed a variant of the PPO reinforcement learning algorithm called GRPO, which is more efficient and has better performance. 3. DualPipe: When training AI models in a multi-GPU environment, many efficiency-related factors need to be considered. The DeepSeek team has designed a new method called DualPipe, which is significantly more efficient and faster.
The traditional meaning of "distillation" refers to the training of token probabilities (logits), and ChatGPT does not open this type of data, so it is basically impossible to "distill" ChatGPT.
Therefore, from a technical point of view, DeepSeek's achievements should not be questioned. Since the reasoning process of OpenAI o1's related thinking chain has never been made public, it is difficult to achieve this result simply by "distilling" ChatGPT.
And Caoz believes that in DeepSeek's training, some distilled corpus information may have been partially utilized, or a small amount of distillation verification was done, but this should have little impact on the quality and value of its entire model.
In addition, optimizing one's own model based on leading model distillation verification is a routine operation for many large model teams, but after all, it requires an Internet API, and the information that can be obtained is very limited, which is unlikely to be a decisive factor. Compared with the massive amount of Internet data information, the corpus that can be obtained by calling the leading large model through the API is a drop in the bucket. It is reasonable to guess that it is more used for verification and analysis of strategies, rather than directly used for large-scale training.
All large models need to obtain corpus training from the Internet, and the leading large models are also constantly contributing corpus to the Internet. From this perspective, each leading large model cannot escape the fate of being collected and distilled, but there is no need to regard this as the key to success or failure.
In the end, everyone is in me and I am in you, and we move forward iteratively.
Second, the cost of DeepSeek is only $5.5 million?
The cost of $5.5 million is both correct and wrong, because it does not make it clear what the cost is.
Tanishq Mathew Abraham objectively estimated the cost of DeepSeek:
First, we need to understand where this number comes from. This number first appeared in the DeepSeek-V3 paper, which was published a month earlier than the DeepSeek-R1 paper;
DeepSeek-V3 is the base model of DeepSeek-R1, which means that DeepSeek-R1 actually performed additional reinforcement learning training on top of DeepSeek-V3.
So, in a sense, this cost data itself is not accurate enough because it does not include the additional cost of reinforcement learning training. However, this additional cost may only be a few hundred thousand dollars.

Figure: Discussion of costs in the DeepSeek-V3 paper
So, is the $5.5 million cost claimed in the DeepSeek-V3 paper accurate?
Multiple analyses based on GPU cost, dataset size, and model size all yield similar estimates. It is important to note that while DeepSeek V3/R1 is a 671 billion parameter model, it uses a mixture-of-experts architecture, which means that only ~37 billion parameters are used in any function call or forward pass, which is the basis for the training cost calculation.
It is important to note that DeepSeek reports costs based on current market prices. We do not know how much their 2048 H800 GPU cluster (note: not H100, a common misconception) actually cost. It is usually cheaper to buy a cluster of GPUs in bulk than in pieces, so the actual cost is likely lower.
But the key point is that this is only the cost of the final training run. There are many small experiments and ablation studies before reaching the final training, which incur considerable costs that are not reflected in this report.
There are also many other costs, such as researcher salaries. According to SemiAnalysis, DeepSeek researchers are reportedly paid as much as $1 million. This is comparable to the high-end salaries of cutting-edge AGI labs such as OpenAI or Anthropic.
Some people deny DeepSeek's low cost and operational efficiency because of these additional costs. This is extremely unfair. Other AI companies also spend a lot of money on salaries, which is usually not factored into the cost of the model. ”
Semianalysis (an independent research and analysis company focusing on semiconductors and artificial intelligence) also gave DeepSeek's AI TCO (total cost in the field of artificial intelligence) analysis. This table summarizes the total cost of DeepSeek AI when using four different types of GPUs (A100, H20, H800 and H100), including the cost of purchasing equipment, building servers and operating costs. Based on a four-year period, the total cost of these 60,000 GPUs is US$2.573 billion, mainly the cost of purchasing servers ($1.629 billion) and operating costs ($944 million).
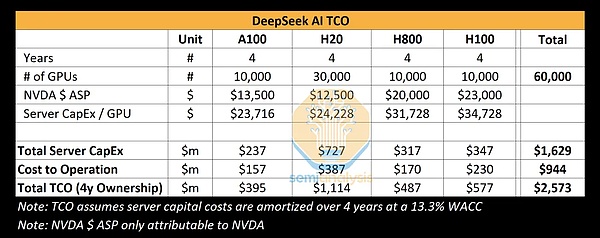
Of course, no one outside knows exactly how many cards DeepSeek has and what the proportion of each model is. Everything is just an estimate.
In summary, if all the costs of equipment, servers, operations, etc. are calculated, the cost will definitely be far more than 5.5 million US dollars. However, the net computing power cost of 5.5 million US dollars is already very efficient.
Third, is the huge capital expenditure investment in computing power just a huge waste?
This is a widely circulated but rather one-sided view. Indeed, DeepSeek has demonstrated its advantages in training efficiency, and it has also exposed that some leading AI companies may have efficiency problems in the use of computing resources. Even Nvidia’s short-term plunge may be related to the widespread spread of this misunderstanding.
But this does not mean that having more computing resources is a bad thing. From Scaling From the perspective of the Laws of Scalability, more computing power always means better performance. This trend has continued since the advent of the Transformer architecture in 2017, and DeepSeek's model is also based on the Transformer architecture.
Although the focus of AI development is constantly evolving - from the initial model scale, to the size of the data set, to the current inference calculations and synthetic data, the core law of "more computing equals better performance" has not changed.
Although Deep Seek has found a more efficient path, the scale law is still valid, but more computing resources can still achieve better results.
Fourth, does DeepSeek use PTX to bypass the dependence on NVIDIA CUDA?
The DeepSeek paper mentioned that DeepSeek uses PTX (Parallel Thread Execution) programming. Through such a customized PTX optimization, DeepSeek's system and model can better release the performance of the underlying hardware.
The original text of the paper is as follows:
"we employ customized PTX (Parallel Thread Execution) instructions and auto-tune the communication chunk size, which significantly reduces the use of the L2 cache and the interference to other SMs."
There are two interpretations of this content on the Internet. One voice believes that this is to "bypass the CUDA monopoly"; the other voice is that because DeepSeek cannot obtain the highest-end chips, in order to solve the problem of limited interconnection bandwidth of the H800 GPU, it has to sink to a lower level to improve cross-chip communication capabilities.
Dai Guohao, an associate professor at Shanghai Jiaotong University, believes that both statements are not quite accurate. First of all, the PTX (parallel thread execution) instruction is actually a component located inside the CUDA driver layer, and it still relies on the CUDA ecosystem. Therefore, it is wrong to use PTX to bypass the CUDA monopoly.
Professor Dai Guohao used a PPT to clearly explain the relationship between PTX and CUDA:
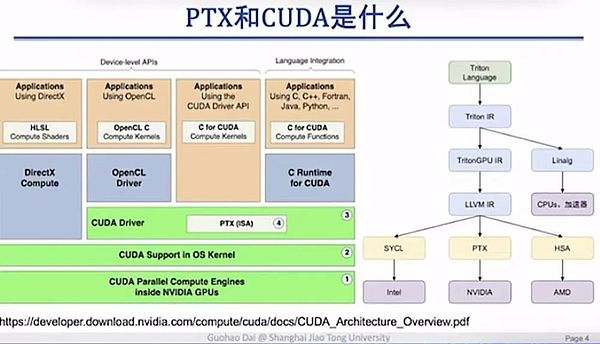
The PPT was made by Dai Guohao, an associate professor at Shanghai Jiaotong University
CUDA is a relatively higher-level interface that provides a series of user-oriented programming interfaces. PTX is generally hidden in the CUDA driver, so almost all deep learning or large model algorithm engineers will not touch this layer.
Why is this layer so important? The reason is that you can see that from this position, PTX directly interacts with the underlying hardware, which can achieve better programming and calling of the underlying hardware.
In layman's terms, DeepSeek is not an optimization solution that is forced to be used under the current conditions of chip limitations, but an optimization that is made proactively. Regardless of whether the chip used is H800 or H100, this method can improve the efficiency of communication and interconnection.
V. Will DeepSeek be banned abroad?
After DeepSeek became popular, the five major cloud giants, NVIDIA, Microsoft, Intel, AMD, and AWS, all launched or integrated DeepSeek. Domestically, Huawei, Tencent, Baidu, Alibaba, and Volcano Engine also support the deployment of DeepSeek.
However, there are some overly emotional remarks on the Internet. On the one hand, foreign cloud giants have launched DeepSeek, and "foreigners have been defeated."
In fact, the deployment of DeepSeek by these companies is more due to commercial considerations. As a cloud vendor, supporting the deployment of the most popular and powerful models as much as possible can provide better services to customers. At the same time, it can also take advantage of a wave of DeepSeek-related traffic, and perhaps also bring in some new user conversions.
It is true that the centralized deployment was carried out when DeepSeek was popular, but the claims that DeepSeek has a special liking or is "beaten to death" are exaggerated.
What's more, some people have fabricated the claim that after DeepSeek was attacked, the Chinese technology circle formed the Avengers Alliance to jointly support DeepSeek.
On the other hand, there are voices saying that due to geopolitical and other realistic reasons, DeepSeek will soon be banned abroad.
In this regard, Caoz gave a clearer interpretation: In fact, the DeepSeek we are talking about actually includes two products, one is DeepSeek, a world-famous App, and the other is the open source code library on GitHub. The former can be considered as the demo of the latter, a complete capability display. And the latter may grow into a thriving open source ecosystem.
The DeepSeek App is restricted, while the giants access and provide the deployment of DeepSeek open source software. These are two completely different things.
DeepSeek has entered the global AI arena as a "Chinese big model" and adopted the most generous open source agreement - MIT License, which even allows commercial use. The current discussion about it has far exceeded the scope of technological innovation, but the progress of technology has never been a black-and-white dispute between right and wrong. Instead of falling into excessive hype or total denial, it is better to let time and the market test its true value. After all, in the AI marathon, the real competition has just begun.
References:
"Some Common Misunderstandings about DeepSeek" Author: caoz
https://mp.weixin.qq.com/s/Uc4mo5U9CxVuZ0AaaNNi5g
"The Strongest Professional Disassembly of DeepSeek is Here, Professor Qingjiaofu's Super Hard-core Interpretation" Author: ZeR0
https://mp.weixin.qq.com/s/LsMOIgQinPZBnsga0imcvA
Debunking DeepSeek Delusions Author: Tanishq Mathew, former research director of Stability AI Abraham
https://www.tanishq.ai/blog/posts/deepseek-delusions.html


 Anais
Anais